Building Vibium Skills That Actually Drive Fixes
Introduction
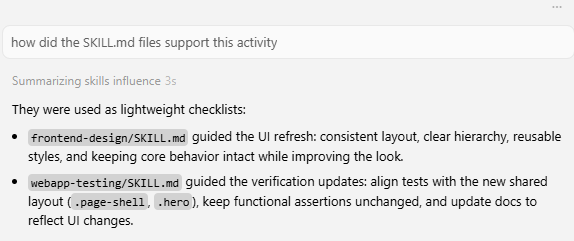
This post is about turning a skills system into a real testing accelerator. I wanted a Vibium-only testing skill that would steer an agent away from Playwright and into purposeful negative tests. That meant carving out a dedicated SKILL.md file, proving the description would be recognised by an agent, and then watching it surface the right failures in the app so I could fix them.
It worked. The agent produced the failing tests, explained why they failed, I corrected the app behaviour, and a clean re-run confirmed the fixes.
As a bonus, I was even able to create a new skill to help me convert the current agent conversation into a blog post – this one in fact!
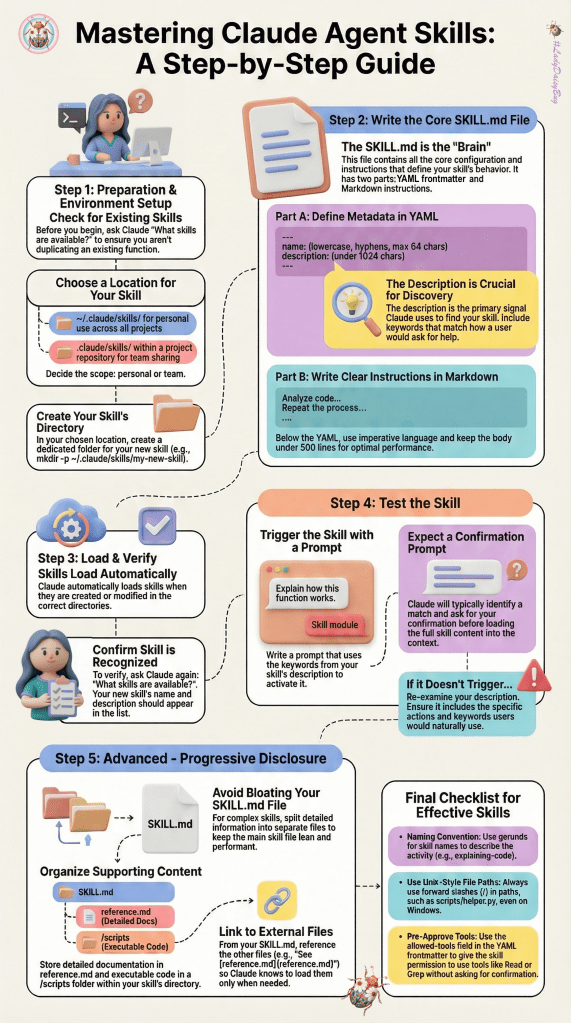
I used this document to guide me in how to create, verify and test Skills.md files

note: thankyou to Lana Begunova for posting these on the Vibium Discord channel this week.
Background: The Project Context
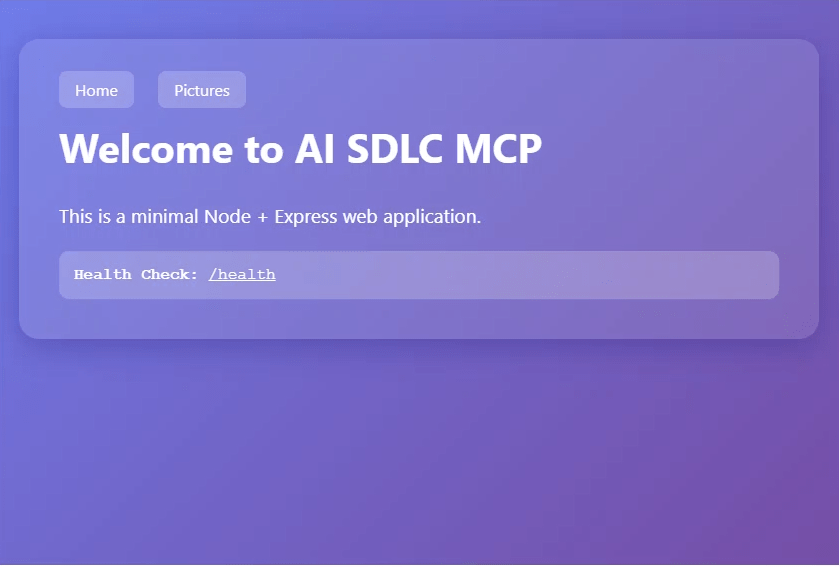
The project is a small Node.js + Express application with a basic health check and an image upload flow. Vibium is used for browser automation tests alongside Playwright, and Cursor skills guide how agents approach testing tasks.
Stack highlights:
Node.js + Express
Vibium for browser automation
TypeScript test files
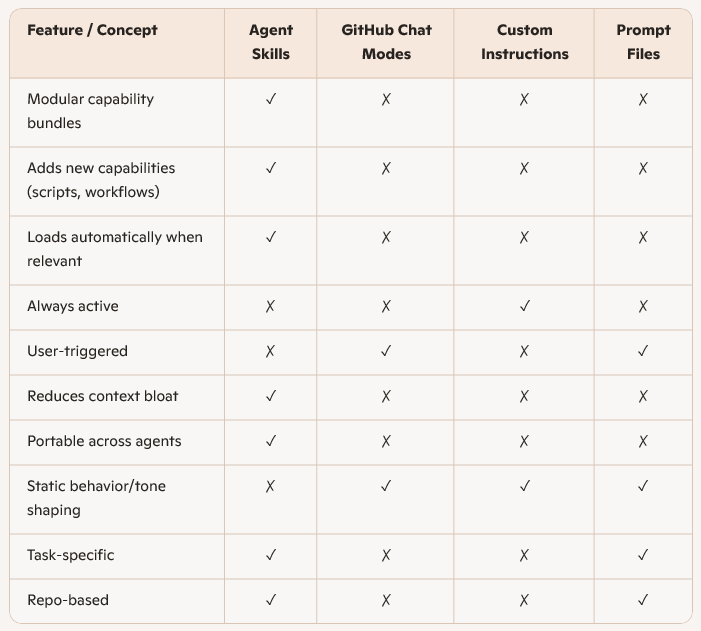
Cursor skills to shape agent behaviour
If you want the full codebase, it’s available here:
https://github.com/askherconsulting/AI_SDLC_MCP
Step 1: Creating a Vibium-only Skill
The existing skills file mixed general testing guidance with Vibium notes. To make the agent reliably select Vibium (not recommended but required in order to confirm I could correctly isolate and test a skills file was being picked up and used), I created a dedicated skill by modifying the existing skill file and isolating only Vibium behaviour.
In practice, I:
Duplicated the original skills content
Removed anything Playwright-specific
Tightened the language to explicitly prefer Vibium APIs and helpers
Saved it as a new skills file focused purely on Vibium tests
That new skill became a single source of truth for Vibium test tasks and prevented drift into Playwright patterns. In reality – you wouldn’t have two test approaches in a single codebase, but this was the best way I had to prove skills worked well, so I ran with it.
Step 2: Proving the Skill Description Worked
An agent skill is only useful if an agent actually picks it up. To validate the description, I ran a quick check using the Claude CLI by asking it to write some Vibium only tests and tell me which, if any, skills file was utilised. The goal was simple: confirm that the skill text was specific enough for an agent to recognise and follow when asked to write Vibium tests.
The CLI output showed the agent selecting the Vibium skill and following its constraints. That gave me confidence the description was precise enough and the new file was discoverable in the skills folder.
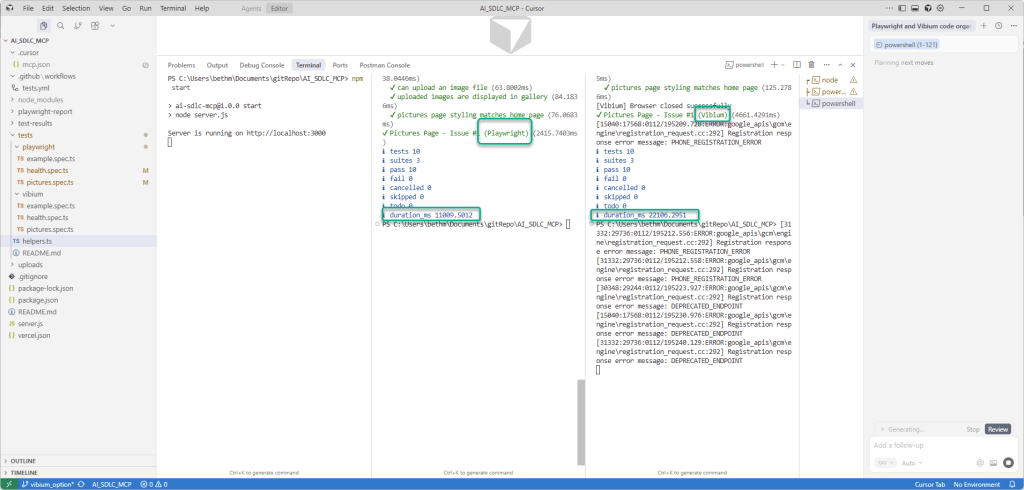
Step 3: Running the Vibium Negative Tests
With the skill in place, I asked the agent to write negative tests for the /health endpoint. The results were excellent:
The tests used Vibium only
They re-used shared helpers
They validated invalid paths and methods
What Failed and Why
When I ran the new negative tests, a few failed in exactly the right way. The agent did not just report failures; it explained the why in plain language:
Trailing slashes were being accepted (Express treats /health and /health/ as the same path by default).
Case variations were being accepted (Express routes are case-insensitive by default).
That explanation mattered. It made it clear this was not a test problem; it was a routing behaviour issue in the app. So instead of wasting my time exploring whether it was a false positive or not, I could go straight to fixing things.
Step 4: Fixing the Underlying App
The fix was small but meaningful. I tightened the routing configuration to enforce exact path matches. This meant that only GET /health would return OK, and variations would be rejected.
With that change in place, I re-ran the same Vibium negative tests. They passed, and the agent’s reasoning lined up perfectly with the new behaviour.
Results: Failing Tests That Led to a Real Fix
This was the best part of the workflow:
The new skill directed the agent to produce Vibium-only tests
The tests failed for legitimate behavioural reasons
The agent explained the root cause clearly
I fixed the app configuration (or Cursor did!)
The exact same tests passed on re-run
That tight loop is the whole point of skills-driven automation: consistent test behaviour plus actionable feedback.
Key Takeaways
A focused skill file makes agent behaviour predictable.
Validating the skill description with Claude CLI avoids false confidence.
Negative tests are most valuable when they trigger meaningful app fixes.
Clear failure explanations speed up root-cause analysis.
Conclusion
By isolating Vibium behaviour into its own skill and verifying the description with Claude CLI, I had confidence in my SKILLS.md file – it was being picked up and used correctly. Modifications to it were also being picked up. Useful insight that I’ll be able to take forward with me when creating new skills files in the future.
Repo: https://github.com/askherconsulting/AI_SDLC_MCP
Tags: Testing, Node.js, Express.js, Vibium, Agent Skills, Negative Testing, API Quality
Creator: Created by AI, reviewed by a human (me!)
Reading Time: ~6 minutes